Current State-of-the-art
Multiple approaches have been proposed for image super-resolution, some using deep learning techniques while others using classical computer vision techniques. The current state-of-the-art [3] proposes an efficient and effective degradation-adaptive super-resolution (DASR) network, which is a novel method for super resolving real-world images. The proposed degradation-adaptive network consists of a degradation prediction network and a CNN-based super-resolution network. It uses a tiny regression network to predict the degradation parameters of each input image, and several convolutional experts to jointly optimize the network parameters.
They compare the proposed DASR with representative and state-of-the-art SR methods by making visual comparisons on real-world images and quantitative comparisons on synthetic datasets and the results show that their approach performs much better than the other existing ones in terms of handling real-world images and is also much more efficient for easy deployment.
Research in the field of SR is evolving and spans over multiple Deep Learning solutions, including both supervised and unsupervised learning techniques. In this project, we go into the details of 2 such methods. The two methods we have chosen to deep dive into and compare cover both - supervised: ESRGAN[2] and unsupervised: ZSSR[1]. We first describe both the methods and then compare them theoretically, as well as with practical and experimental results.
Generative Adversarial Network (GAN) is now a popular approach in the SR field, often referred to as SRGAN. GAN uses a complete dataset of high resolution images for training purposes. A GAN possesses two main parts: a generator and a discriminator. The generator learns how to create the dataset distribution from random noise and the discriminator learns how to distinguish between real samples from the dataset and synthetically created samples from the generator. By training them together in an adversarial manner, each part is improved iteratively and the end result is a strong sample generator and a strong classifier for real vs. fake samples.
Empirical evidence shows that this approach is bound by an intrinsic tradeoff property. This method struggles to improve performance with regards to noise (distortion) and perceptual (quality) metrics simultaneously. In simpler terms, the more real a super-resolved image appears, the more noise or artifacts it has that might be of synthetic origin, and the less distortion and noise in the super-resolved image the blurrier it will look.

Figure 3
ESRGAN improves on top of SRGAN to tackle this problem and enhance the performance and results. This is done using network interpolation and by adding a relativistic discriminator. The advantage is that the network is trained not only to tell which image is true or fake, but also to make real images look less real compared to the generated images, thus helping to fool the discriminator. Batch normalization in SRGAN is also removed, and Dense Blocks (inspired from DenseNet) are used for better information flow. These Dense Blocks are called RRDB.

Figure 4: Changes done in ESRGAN in network architecture
ESRGAN is a supervised deep learning approach to SR. Now we move on to unsupervised technique, ZSSR.
"Zero-Shot" Super-Resolution - ZSSR
Zero-Shot SR uses the Deep Internal Learning method which does not rely on prior training, instead learns from the internal recurrence of information in an input image. This approach exploits the fact that natural images have strong internal data repetition.
ZSSR achieves this by first downscaling the input LR images I, and generates a lower resolution version of itself, Is (here, s is the desired SR scale factor). Then, a relatively light CNN is trained to reconstruct the original image I from its lower-resolution version Is. Finally, this trained CNN is applied to the image I (as input to the network) to construct the desired HR output Is (s being the same scale factor as above).
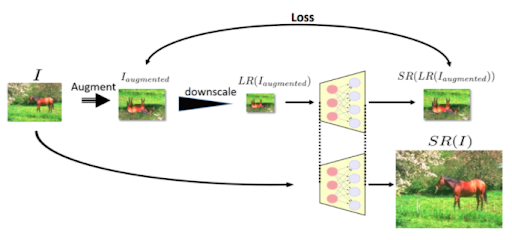
Figure 5: ZSSR training process
Comparison
Following figure shows a high-level difference between supervised (like ERSGAN) and unsupervised ZSSR methods layout. Supervised method trains on a large and diverse external collection of Low resolution(LR)-High Resolution(hR) examples. These methods aim to capture the large diversity of all possible LR-HR relations in their learned weights. On the other hand, because ZSSR trains on the target images itself, the diversity of LR-HR relations in such single images is significantly smaller. Thus, simpler and smaller networks are enough for training, unlike supervised models, where networks are often extremely deep and very complex. Supervised methods tend to not deal very well with unseen classes, ZSSR doesn't have this problem because of the same train and test data.

Figure 6: High level difference between supervised and unsupervised ZSSR methods